

马德里,4 月 8 日(路透社)——西班牙可再生能源集团 Capital Energy 周五宣布与谷歌(GOOGL.O)的云计算服务结盟,以加快数字化、降低碳足迹并提高其数据保留和分析能力。
该公司表示,该合作最初将持续五年,将使 Capital Energy 能够利用其风力涡轮机和太阳能电池板上数千个传感器的数据,以延长其资产的使用寿命、降低成本并增加收入。
Capital 表示,它还应该降低网络安全漏洞的风险。
Capital Energy 的数字化和可持续发展总监在一份声明中表示:“谷歌云的愿景与我们相似,这使其成为我们理想的旅行伴侣。”
这家能源公司是西班牙能源市场的新成员,渴望成为伊比利亚半岛上第一家完全可再生能源运营商。
Capital 表示,它还应该降低网络安全漏洞的风险。
Capital Energy 的数字化和可持续发展总监在一份声明中表示:“谷歌云的愿景与我们相似,这使其成为我们理想的旅行伴侣。”
这家能源公司是西班牙能源市场的新成员,渴望成为伊比利亚半岛上第一家完全可再生能源运营商。

圣保罗,4 月 7 日(路透社)——Facebook 所有者 Meta Platforms (FB.O)周四表示,它已经删除了一个与巴西军方有联系的社交媒体账户网络,这些账户伪装成虚假的非营利组织,以淡化森林砍伐的危险。
一位知情人士说,虽然参与网络的个人是现役军人,但 Meta 的调查没有找到足够的证据来确定他们是否遵守命令或独立行事。
Meta 的季度报告可能会对巴西总统 Jair Bolsonaro 造成损害。这位极右翼的前陆军上尉长期以来一直对环保主义持怀疑态度,他已将武装部队部署到亚马逊,但未能成功执行减少对世界上最大热带雨林的破坏的任务。阅读更多
拆除行动是 Meta 首次打击主要关注环境问题的网络,也可能会加剧 Bolsonaro 对大型科技公司的攻击,他指责这些公司扼杀了他们平台上的保守派声音。
批评人士说,博尔索纳罗和他的支持者利用这些平台传播危险的虚假信息,破坏巴西的民主制度。
Meta 在其报告中表示,该网络在规模和真实参与方面受到限制,最初使用 Facebook 和 Instagram 上的虚假账户发布有关 2020 年土地改革和大流行的信息,然后在去年将重点转向环境问题。
“在 2021 年,他们创建了以虚构的非政府组织和活动家的身份关注巴西亚马孙地区环境问题的页面。他们发布了关于森林砍伐的帖子,包括认为并非所有森林都是有害的,并批评了公开反对森林砍伐的合法环境非政府组织在亚马逊,”Meta 在其报告中说。
“尽管(网络)背后的人试图隐瞒他们的身份和协调,但我们的调查发现与巴西军方有关的个人存在联系。”
Meta 拒绝提供有关其调查的更多信息。
巴西军方在一份声明中表示,它知道 Meta 的指控,并已与该公司联系,以获取支持其军事参与声明的数据。
它说它要求所有成员都实践“真实、正直和诚实”。
博尔索纳罗的办公室没有回复置评请求。

路透社获得的这张未注明日期的讲义图片中可以看到 Nvidia 在芯片制造商的 AI 开发者大会上推出的新 Grace CPU 超级芯片。英伟达/路透社的讲义
4 月 8 日(路透社)——芯片制造商英伟达公司(NVDA.O)周五表示,将寻求股东批准将普通股的授权股数从 40 亿股增加到 80 亿股。
关于俄罗斯的 Twitter 微博服务,已经制定了另一项关于行政违法的协议。法庭听证会后,拥有该服务的公司可能会被处以最高 400 万卢布的罚款。
Twitter 被指控不删除在俄罗斯被禁止的信息。4 月 28 日,莫斯科世界法院将对这一事实进行审议并作出决定。“会议将于 11:00 在莫斯科市塔甘斯基区第 422 号司法地点举行,” RBC在法庭上被告知。
根据塔斯社的说法,微博服务可能会因未删除包含纳粹符号、恐怖主义和极端主义理由的出版物以及包含在家制造爆炸物说明的材料而承担责任。
根据该公司的正常罪行,罚款可达400万卢布。迄今为止,俄罗斯对 Twitter 的罚款总额已达 6600 万卢布。该公司因未删除禁止信息和拒绝将俄罗斯用户的个人数据本地化在俄罗斯联邦境内而受到处罚。自 3 月初以来,俄罗斯一直在限制使用该服务。
Atlassian 仍在努力从最近的软件脚本惨败中恢复,并希望不会丢失任何客户数据,如果 OneDrive 正如一些人所报道的那样,至少两个月来间歇性地破坏大型上传,这可能超出微软所能管理的范围。
在一些 Atlassian 客户开始遇到这家云巨头的协作软件问题四天后,恢复工作仍在继续,一些人担心他们可能无法取回数据。
在该公司通过 Twitter 回应了确认客户数据已备份但未能实际备份的请求后,有人写信给The Register想知道这种可能性。
该公司周四表示: “我们预计大多数站点恢复都会发生最少或没有数据丢失的情况。”
当然,最小的数据丢失与没有数据丢失是不一样的,对于那些受影响的人来说,这是可以理解的。
“这对我们来说非常令人担忧,因为我们的关键任务机构知识目前存在于 Confluence 中,”一位要求匿名的 Atlassian 客户在给The Register的电子邮件中说。“而且这条消息与我们一遍又一遍地收到的‘维护脚本已禁用少数站点’的消息背道而驰。这也可以解释为什么这么多工程师 24/7 工作需要几天时间。 '"
地图集
Atlassian Jira,Confluence 中断持续两天
阅读更多
The Register向 Atlassian 询问了 IT 故障,从该公司的状态页面来看,该故障仍然是一个持续的事件。周四快结束时,Atlassian 的发言人发表了一份令人放心但类似的声明。
发言人说:“我们正在继续调查并解决这一事件。” “在这个时间点,我们相信任何潜在的数据丢失都将是微乎其微的。我们正在努力解决这一事件,让客户重新上线。”
我们还被告知,该事件影响了相对较少的 Atlassian 客户:大约 400 名。这仅占公司 226,000 名客户的 0.18%,这对于数百名仍然无法访问其数据的客户来说并不算什么安慰。
当我们周五与读者核对时,问题尚未解决。
“我们还没有恢复任何数据,这些服务都处于关闭状态,”我们的消息人士说。“我们没有获得任何 ETA 访问权限。”
服务完全恢复后,Atlassian 可能会使用其Incident Postmortem Template提供有关所发生情况的详细报告。
微软卸载
与此同时,微软的 OneDrive 显然已经断断续续地破坏大型、多部分文件上传至少两个月。
标记该问题的报告可以追溯到 2 月初,当时它们出现在备份应用程序 Duplicati的论坛帖子中。另一个备份应用程序 rclone 的用户早在 2022 年 3 月 24 日就开始讨论似乎是同一问题的问题。
三天前,rclone 的创建者 Nick Craig-Wood向微软 OneDrive 的 GitHub存储库发布了一份错误报告。“有时(可能是 20 次)128MiB 文件的分段上传会损坏,”他的帖子解释道。
其他 多个人说他们已经重现了这个偶尔出现的错误。
“在今天早上的测试中,我仍然看到了问题,”GitHub 用户“rleeden”写道。“我创建了一个包含 128M 和 256M 之间随机数据的 100 个文件的随机测试层次结构,并通过 Web 界面将其上传到 OneDrive。”
“检查原始文件的sha1sum和OneDrive上的文件,我发现100个文件中有16个已损坏。”
然后在星期四,这个人无法重现错误,这表明微软的某个人可能已经修复了这个错误。”而且 Craig-Wood还报告说不再看到损坏的文件。
The Register询问微软,微软在提交错误报告时以编程方式提醒该公司是否有人修复了 OneDrive,如果是,是否会向可能没有意识到他们上传的某些内容的 OneDrive 用户发布任何公告损坏。
Paul Scherrer 研究所和苏黎世联邦理工学院的研究人员成功实现了一项技术突破,这可能会导致新形式的低能耗超级计算。
它基于一种叫做人造自旋冰的东西:想象水分子冻结成冰晶格,然后用磁性纳米晶体代替水。构建良好自旋冰的关键是将磁性粒子变得如此之小,以至于它们只能通过将它们降低到一定温度以下来极化或“旋转”。
当这些磁铁被冻结时,它们会排列成格子状,就像水冰一样,但具有重新排列成近乎无限的磁性组合的额外潜力。在这里,用例开始出现,这个实验的一些突破可以让我们朝着正确的方向前进。
这一发现由 PSI 物理学家 Kevin Hofhuis 和 PSI 研究人员/苏黎世联邦理工学院教授 Laura Heyderman 和 Peter Derlet 完成,可以为低能 HPC 应用铺平道路,并在油藏计算中具有额外的潜在用途,其中涉及使用更高维度的固定线性系统比信号映射的输入。“有许多领域可以应用水库计算,包括天气和金融市场预测、图像和语音识别以及机器人技术,”Hofhuis 说。
海德曼甚至推测,高速、低功耗的自旋冰超级计算机可能类似于人脑:“该过程基于大脑中的信息处理,并利用人造自旋冰对刺激的反应,例如磁场或电流。”
旋转冰背后的科学
需要明确的是,这奠定了基础,但旋转冰超级计算机不是在不久的将来。这并没有阻止研究人员推测如何使用旋转冰和相变的操纵。
“理论上已经预测了人造kagome旋转冰的磁相变,但以前从未观察到它们,”海德曼说,他已经在旋转冰上进行了十多年的 研究和发表。
在这个实验中,一种称为坡莫合金的镍铁化合物被铺展在硅基板上,然后以六边形图案光刻在基板上,每个都通过这些桥连接,这些桥是使他们能够调整和观察相变的关键。
正如 Hofhuis 解释的那样,kagome形式的每个磁体(一个环由六个磁体组成)有两个排列,这意味着 64 个潜在的磁态。两个环将其增加到超过 2,000 种可能的状态,依此类推。Hofhuis 说:“在我们拥有数千个纳米磁体的大型阵列中,存在着难以想象的大量磁态。”
实验团队取得了两项重大突破:在磁体之间建立了纳米级磁桥,使它们的响应更加可预测,并验证了阵列中纳米磁体的磁态如何随时间演变。后一个发现需要一个特殊的显微镜和一个 X 射线同步加速器,但让他们看到自旋冰中的实际相变。
这些桥只有 10 微米厚(一根人的头发大约 70 微米),研究人员能够捕捉到纳米磁体相互作用的视频,但除了推断发生在相变的时刻。
Hofhuis 说他需要 Derlet 设计的模拟来证明他所记录的是相态变化。“只有将记录的图像与这些模拟进行比较,才能证明在显微镜下观察到的过程实际上是相变,”PSI 说。
在一天结束时,研究人员生产并测量了人造kagome旋转冰,它足够小,可以做旋转冰应该做的事情:只能通过温度诱导的磁相变形成。使用它进行超级计算将需要更多时间

新加坡,2022年4月8日——随着边境限制的放松,新常态下,世界各地的采矿业通过数字化适应了自 100 多年前首次开发现代采矿技术以来的前所未有的速度。IDC预测,到2022年,前100名矿工中的 75% 将在整个运营过程中操作远程和自主钻机,从而提高设备效率。这是 IDC 在其最近的报告IDC FutureScape:2022 年全球矿业预测中公布的预测之一,并在IDC FutureScape 网络广播:2022 年 全球矿业预测中进行了讨论。
“在2022年,我们预计将看到从快速部署远程工作技术中学到的知识的整合,这为培养远程操作和自动化机械所需的人才奠定了良好的基础。矿工们已经采用 DX 来维持惊人的产量,我预计IDC Energy Insights Worldwide Mining 高级研究经理Ben Kirkwood说,这种积极影响将在未来五年内对该行业产生积极影响。
以下是将塑造矿业组织在未来12-36 个月内如何在数字优先世界中运营的重要战略预测:
#1:增加远程设备采用率——由于大流行,到 2022 年,前 100 名矿工中的 75% 将在整个运营过程中操作远程和自主钻机,从而提高设备效率。
#2:弹性连接——到2022年,5%的全球采矿作业将成为 5G 的早期采用者,以利用可靠、低延迟的连接依赖技术,提高安全性、可持续性和运营绩效。
#3:可持续受控运营——到2023年,80%的矿业组织将使用可持续性 KPI 作为其主要运营控制参数的一部分,以帮助实现其组织环境、社会和治理目标。
#4:数字化人才——到2023年,前100家矿业组织中的 25% 将利用增强现实技术进行运营维护,将现场劳动力需求降低 20%。
#5:提高OT安全性——到2023年,前5大矿业组织中的4个将创建OT特定安全部门,因为组织正在努力实现安全的物联网实施。
#6:可审计的可追溯性——提高可持续性和运营跟踪能力,到 2024 年,10% 的金属生产将使用区块链来跟踪和监控商品从原产地到最终产品的价值链。
#7:增强运营——到2024年,50% 的顶级矿业组织将利用基于云的运营规划和模拟工具,提供决策支持、更强大的分析和改进的优化能力。
#8:生态系统范围的合作伙伴关系——到 2025 年,80% 的组织将与主要供应商合作利用设备即服务模式,为关键运营设备和系统提供支持。
#9:集成流程——到2025年,排名前 5 位的矿业组织将部署基于云的平台,以在其价值链中提供洞察力,支持工人的自助服务和单一的事实来源。
#10:卫星支持的转型——到2026年,随着部署卫星的成本迅速下降,一个采矿组织将拥有自己的卫星在轨,以支持其数字采矿转型。
本 IDC 报告包含 IDC Energy Insights 分析师团队对 2022-2027 年全球采矿业的展望。展望是通过构成未来一年 IT 和业务线 (LOB) 决策者和影响者技术相关计划框架的 10 项预测的视角呈现的。
让 HPC 中的 3D V-Cache 时代开始。
研究人员受到AMD “Milan-X” Epyc 7003 处理器及其 3D V-Cache堆叠 L3 高速缓存的想法的启发,然后通过实际基准测试将常规 Milan CPU 与使用真实和合成 HPC 应用程序的 Milan-X 处理器进行对比。在日本的 RIKEN 实验室,基于富士通令人印象深刻的 A64FX 矢量化 Arm 服务器芯片的“Fugaku”超级计算机已经启动了对假设的 A64FX 后续产品的模拟,理论上,该产品可以在 2028 年建造,并提供近一个订单性能比当前的 A64FX 高出很多。
早在 2021 年 6 月, AMD 就让全世界知道它正在为台式机和服务器处理器开发 3D V-Cache ,并展示了一款定制的 Ryzen 5900X 芯片,其芯片顶部具有堆叠的 L3 缓存,仅用一个堆栈就将其容量增加了三倍。(堆叠式 L3 的密度是其两倍,因为它没有芯片上“真正的”L3 缓存所具有的任何控制电路;堆叠式缓存实际上是搭载在芯片上缓存管道和控制器上的。)去年秋天,在 SC21 超级计算大会之前,AMD 公布了 Epyc 7003 CPU 阵容中 Milan-X SKU 的部分特性,而 Milan-X 芯片于今年 3 月亮相
我们认为 3D V-Cache 最终将用于所有处理器,一旦制造技术完善且足够便宜,正是因为这将释放裸片区域以专用于更多计算内核。(我们在接受AMD 高级副总裁兼服务器业务总经理Dan McNamara 采访时讨论了这一点。
RIKEN 的研究人员与东京工业大学和日本国立先进工业科学技术研究所、瑞典皇家理工学院和查尔姆斯理工大学以及印度理工学院的同事合作,得到了他们的手配备 AMD Epyc 7773X (Milan-X) 和 Epyc 7763 (Milan) 处理器的服务器,并运行 MiniFE 有限元代理应用程序——美国 Exascale Computing Project 用于测试 exascale HPC 机器规模的重要代码之一– 在两台机器上显示额外的 L3 缓存有助于将性能提高 3.4 倍。看一看: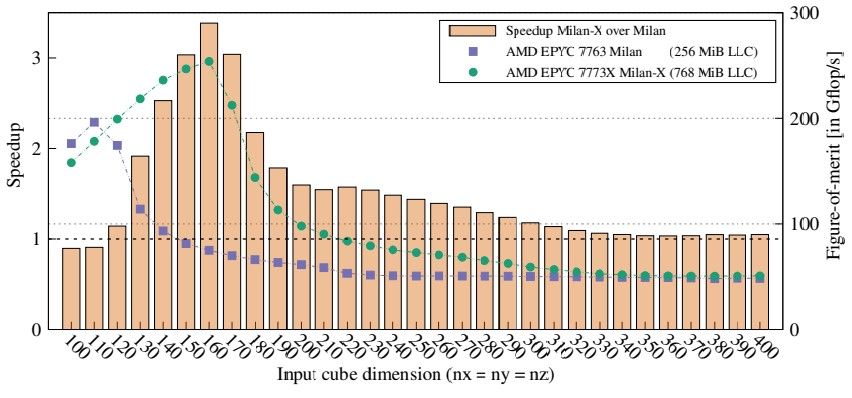
在 HPC 世界中,3.4X 没什么可动摇的。这让 RIKEN 团队开始思考:如果将 3D V-Cache 添加到 A64FX 处理器会发生什么?更具体地说,这让他们开始思考如何将 3D V-Cache 与假设的 A64FX 踢球器结合起来,根据使用 Sparc64 的“K”超级计算机之间的节奏,预计这将在大约六年左右的时间里完成—— 2011 年的VIIIfx 处理器和基于 A64FX 的 Fugaku 超级计算机从 2020 年开始。因此,他们启动了 Gem5 芯片模拟器,并模拟了具有大型 L2 缓存的未来 A64FX kicker(A64FX 没有共享 L3 缓存,但确实有大型共享 L2 缓存),它正在替代 LARC对于大型缓存,可能看起来像以及它在 RIKEN 代码和流行的 HPC 基准上的表现。
这就是创建数字双胞胎的力量,恰如其分地说明。如果你阅读 RIKEN 及其合作者发表的论文,你会发现这项任务并不像 Nvidia 和 Meta Platforms 广告中看起来那么顺利,但它可以做得很好,以获得一阶近似值强制资助未来的研究和开发。
我们对深谷系统中的技术进行了多次深入研究,但最重要的是 2018 年的这一块。这张 A64FX 处理器的照片是开始讨论假设的 A64FX kicker CPU 的好地方:
A64FX 有四个核心内存组,即 CMG,它们具有由富士通 13 核创建的定制 Arm 核心、一大块共享 L2 缓存和一个 HBM2 内存接口。每个组中的一个核心用于管理 I/O。剩下 48 个内核可供用户寻址并进行计算;每个内核都有一个 64 KB 的 L1 数据缓存和一个 64 KB 的 L1 指令缓存,而 CMG 有一个 8 MB 的分段 L2 缓存,每个内核有 32 MB 切片。该设计没有 L3 缓存,这是故意的,因为 L3 缓存经常引起比其价值更多的争用,富士通一直相信在其 Sparc64 CPU 设计中尽可能大的 L2 缓存,而 A64FX 将这一理念发扬光大。L2 缓存在每个 CMG 中的内核中具有 900 GB/秒的带宽,因此 A64FX 处理器的总 L2 缓存带宽为 3.6 TB/秒。
信不信由你,RIKEN 没有 A64FX 处理器的平面图,不得不从 die shot 和其他规格估计它,但它是作为Gem5 模拟器的起点,它是开源的,被很多人使用的科技公司。(如果没有富士通的批准和审查,这个估计是不可能完成的,尽管是非官方的,因此我们认为用于 A64FX 的平面图是绝对准确的。)
一旦有了 A64FX 平面图,RIKEN 团队就假设 1.5 纳米工艺将在 2028 年用于出货处理器。这种显着的缩小使得 LARC 假设芯片中的 CMG 的大小只有所用芯片的四分之一在 A64FX 中,这意味着 LARC 处理器可以有 16 个 CMG。假设 L2 高速缓存可以以类似的速度和规模缩小,LARC 芯片的想法是让八个 L2 高速缓存管芯通过芯片接口 (TCI) 将它们粘合在一起,类似于硅通孔 (TSV) ) 用于 HBM 内存堆栈。RIKEN 认为这种堆叠内存可以在 1 GHz 左右运行,基于对堆叠 SRAM 的模拟和其他研究,从下面的比较 CMG 图可以看出,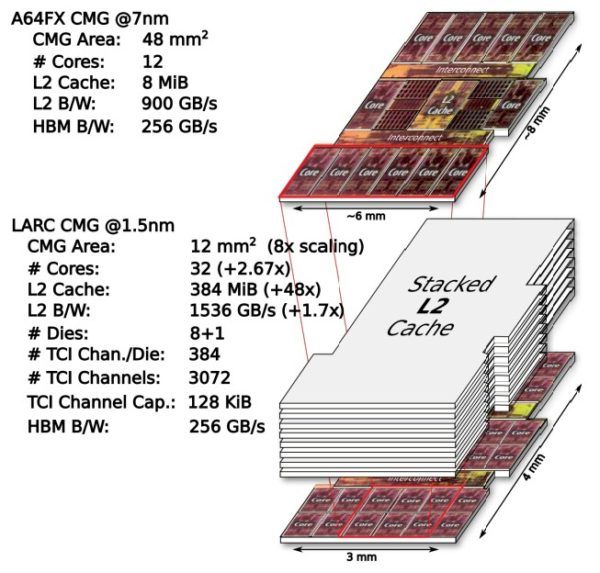
这是一个重要的区别,因为 AMD 的 3D V-Cache 仅将 L3 缓存堆叠在 L3 缓存之上,而不是计算芯片。但我们在这里谈论的是 2028 年,我们必须弄清楚人们会弄清楚在 CPU 内核上安装 L2 缓存的散热问题的材料。以 1 GHz 运行,LARC 的 CMG 中 L2 缓存的带宽将为 1,536 GB/秒,比 A64FX 快 1.7 倍,缓存容量为每个 CMG 384 MB 或 6 GB插座。此外,RIKEN 估计 CMG 将有 32 个内核,是 2.7 倍的倍数。
为了隔离堆叠 L2 缓存对 LARC 设计的影响,RIKEN 将 HBM2 内存保持在 HBM2 级别,并没有模拟 HBM4 的外观,并将 HBM 内存容量保持在 256 GB。我们想知道具有如此高 L2 缓存带宽的 CMG 是否可能不受 HBM2 带宽的限制,而 512 核 LARC 插槽的整体性能可能会受到相对较低的 HBM2 带宽和低容量(仅 8 GB)的抑制每个 CMG)。但是坚持使用 HBM2,每个 CMG 一个控制器,在 LARC 上有 16 个 CMG,即每个 LARC 插槽只有 128 GB 的 HBM2 内存和 4 TB/秒的带宽。假设核心和非核心区域的时钟速度没有太大变化,我们猜想,为了让真正的 LARC 设计保持平衡,可能会提高 4 倍。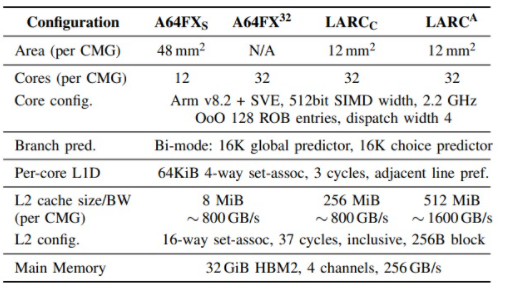
为了隔离内核差异的影响,RIKEN 研究人员设计了一个 32 核 CMG,但每个 CMG 的缓存大小为 8 MB,带宽为 800 GB/秒。只是为了好玩,他们创建了一个 LARC 设计,具有 256 MB 的 L2 缓存和相同的 800 GB/秒带宽(大概只有四个 L2 堆栈)以隔离容量对 HPC 性能的影响,然后在 512 MB 上完成以 1.5 GB/秒的速度运行的 L2 缓存。顺便说一句,LARC 内核中的内核与 A64FX 中使用的自定义 2.2 GHz 内核相同——这里也没有变化。而且你很清楚,到 2028 年,富士通、Arm 和 RIKEN 将拥有更好的内核,但可能没有更好的 512 位向量。(我们将看到。)
以下是假设的 LARC 和实际的 A64FX 芯片在 STREAM Triad 内存带宽基准测试中相互测量的方式: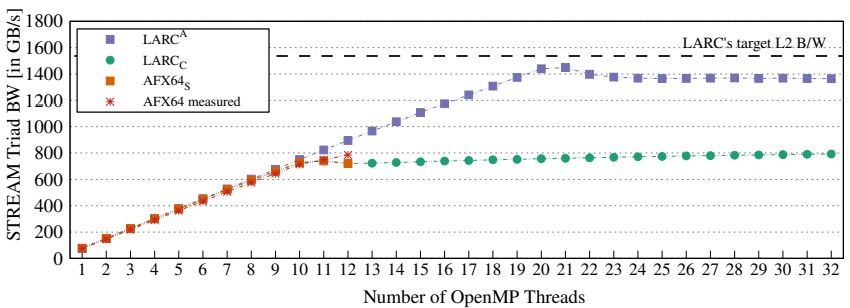
该测试显示带宽随着 OpenMP 线程数量的增加而增加,下面的测试显示了 STREAM 性能如何随着向量输入数据的大小从 2 KB 变为 1 GB 而变化。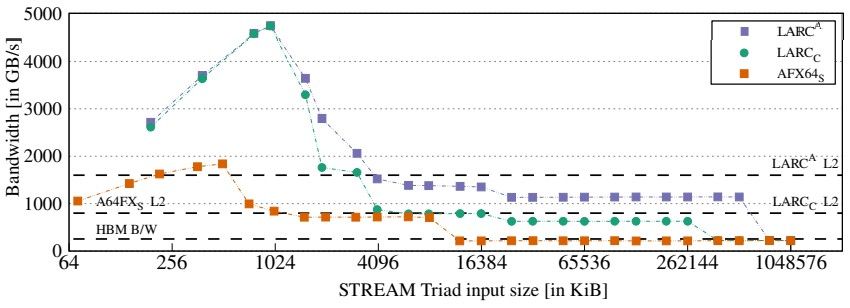
LARC 行的峰值是因为 CMG 中的内核数量是 2.7 倍,而 L1 缓存的数量也是 2.7 倍,因此较小的向量都适合 L1 缓存;然后较大的向量现在可以长时间放入 L2 缓存中。因此,模拟的 LARC 芯片只会启动它,直到所有这些缓存用完为止。
在所有模拟之后,这是重要的事情。在一系列广泛的 HPC 基准测试中,包括在 RIKEN 和其他超级计算机中心运行的实际应用程序以及我们都知道的大量 HPC 基准测试,LARC CMG 平均能够提供大约 2 倍的性能,并且高达 4.5 X 用于某些工作负载。再加上四倍的 CMG,你看到的 CPU 插槽的性能可能会提高 4.9 到 18.6 倍。对于那些对 L2 缓存敏感的应用程序,A64FX 和 LARC 之间的性能改进几何平均值为 9.8 倍。顺便一提:
Gem5 模拟在 CMG 级别运行,因为 Gem5 模拟器无法处理具有 16 个 CMG 的完整 LARC 套接字,并且 RIKEN 不得不对这种规模将如何在套接字中发挥作用做出一些假设。

行业基准很重要,因为无论这种比较是可恶的,IT 组织仍然必须让它们来规划他们未来系统的架构。
由谷歌、百度、哈佛大学、斯坦福大学和加州大学伯克利分校创建的 MLPerf 人工智能基准套件有很多希望,尤其是当谷歌、英特尔和英伟达在 2018 年发布第一个基准测试结果后不久管理 MLPerf 测试的 ML Commons成立。
这个想法是为了让决策者拥有大量数据来决定使用哪些设备进行机器学习、训练和推理,以及从移动设备到边缘机器再到数据中心系统的一切。
但它并没有像标准性能评估公司(SPEC) 的 CPU 级测试、事务处理委员会(TPC)的应用级基准,甚至是 ERP 软件巨头运行的特定测试那样成为无处不在的基准测试SAP 在各种各样的铁上,MLPerf 测试并没有以同样的方式起飞。这通常只是一个检查谁出现了谁没有出现的游戏。许多芯片制造商及其系统合作伙伴并不总是出现,即使出现,他们也不会定期出现,这从 MLPerf 四年前首次推出结果以来就一直困扰着它。
于是这周再次发布了机器学习推理的 MLPerf Inference 2.0 结果,标志着推理结果的第五次发布。(MLCommons 每季度都会发布结果,第一季度和第三季度进行推理,第二季度和第四季度进行培训。)根据 MLCommons 的说法,反应非常强烈,创下了 3,900 多项性能结果的新记录(是前一轮)和 2,200 次功率测量(是之前的六倍),表明人们越来越关注效率。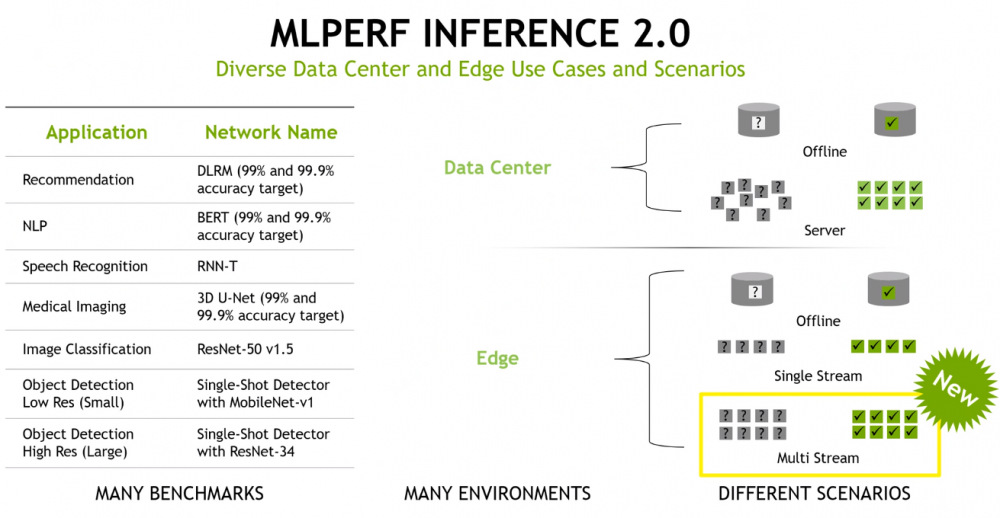
由于更多的系统制造商参与其中,总体参与度也有所上升。也就是说,英伟达(将人工智能作为平台提供商的发展雄心放在首位和中心)和高通(提交了某些测试的结果)是唯一提交结果的芯片制造商,这一点是首席分析师 Karl Freund Cambrian-AI Research在福布斯专栏中写道,并在 Nvidia 与记者和分析师的演示中询问了该公司的业绩。
在人工智能和机器学习正在成为现代工作负载的驱动力以及制造加速器或人工智能优化处理器的硅供应商数量不断增长之际,亚马逊网络服务、英特尔、谷歌、Graphcore、SambaNova和Cerebras Nvidia 产品营销经理。
Salvatore 强调了行业基准作为一种工具的重要性,它可以为用户提供编号,以便在从性能和能效到成本的各个方面比较竞争产品。然而,事情发生了变化。
“我们在过去几年中看到的一个问题——实际上是自大约十年前开始的深度学习革命开始以来——是结果往往以一种狂野的西部方式发布,”他说过。“它们没有可比性。换句话说,一家公司会声称,“我们提供了如此出色的 ResNet-50 分数”,然后这里的另一家公司会说他们有 ResNet-50 分数,但要么他们没有透露具体如何他们得到了这个数字,或者,如果您阅读脚注,您很快就会意识到每家公司的做法都不同,以至于您可能无法真正比较结果。”
Salvatore 认为,MLPerf 为比较平台提供了一个通用的衡量标准。
“人工智能与我们之前拥有行业标准基准的工作负载没有什么不同,”他说。“您需要这些类型的基准来采用通用的测量方式,以便可以直接比较结果,以便客户可以做出数据驱动的购买决策。最终,行业标准基准所扮演的角色是创建通用标准。”
更多的是进入这个行业。老牌基准测试组织 SPEC 上个月成立了 SPEC ML 委员会,为 AI 和机器学习推理和训练制定基准测试标准。
目前尚不清楚新的基准是否会吸引更多的芯片制造商参与,但有一些方法可以改进现在正在做的事情。与启动基础设施和运行工作负载以达到基准相关的成本可能令人望而生畏,尤其是在一年这样做四次的情况下。并不是每个供应商的产品发布都在同一个时间表上。英伟达的芯片可能已经准备好进行基准测试,而此时英特尔仍在等待其部分芯片上市。
英伟达的大量存在也是一个因素。到目前为止,该公司提交的结果比其他任何人都多。即使这一次,当英特尔和 AWS 没有参与时,英伟达也为他们提交了结果,让其他公司可以利用它的数量。
MLPerf——即使是最新的 MLPerf Inference 2.0——也有功耗数据,并且没有附加到基准产品的价格,有效地消除了大多数企业一直拥有的每瓦性能价格比计算的三个部分中的两个预算有限,在考虑购买什么时使用。
很高兴知道在运行推理工作负载时一个芯片比另一个芯片快多少,但如果无法查看芯片将使用多少功率或它们将占用多少有限预算,那么对于一个组织做出明智的决定。
就结果而言,英伟达在数据中心和边缘表现出了强大的性能。该供应商将其 A100 GPU与英特尔的Xeon “Cooper Lake” 8380H 和“Ice Lake” 8380 服务器 CPU(由 Nvidia 提交)以及高通的 AI 100 机器学习芯片运行,在一系列模型中显示出显着优势,包括用于图像的 ResNet-50分类工作负载,用于自然语言处理的 BERT-Large 和用于医学成像的 3D U-Net。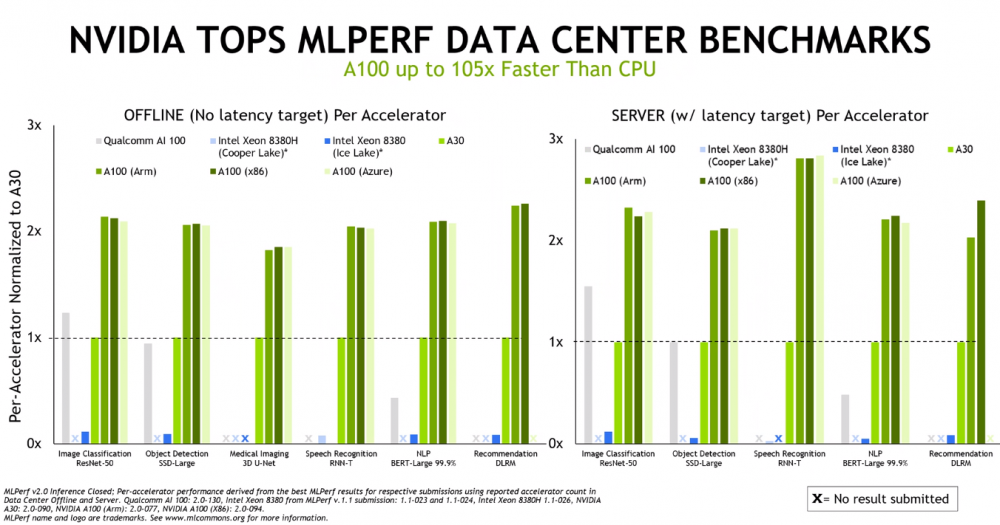
无论是与 x86 芯片、Arm 处理器还是 Microsoft Azure 云实例一起使用,GPU 的性能基本相同。
Nvidia 的 Salvatore 指出,作为其多实例 GPU (MIG) 技术的一部分,供应商可以将单个 A100 GPU 划分为七个实例,并在每个实例中单独运行来自基准测试的工作负载,该芯片可以同时运行所有 MLPerf 测试,对性能的影响约为 2%。他说,这反驳了 A100 只适用于大型网络的论点。
“您还可以使用 MIG 将该 GPU 划分为多个实例,并在每个实例中托管单独的网络,”他说。“这些实例中的每一个都有自己的计算资源、自己的缓存数量和自己的 GPU 内存区域来完成工作。您可以点亮整个部分以达到最佳利用率水平,并能够在单个 GPU 上托管多个网络。对于希望在单个 GPU 上运行多个网络的客户来说,这里有一个很好的效率机会。”
Nvidia 还针对高通公司的芯片测试了 A100 的每瓦性能,再次显示出强劲的效率结果。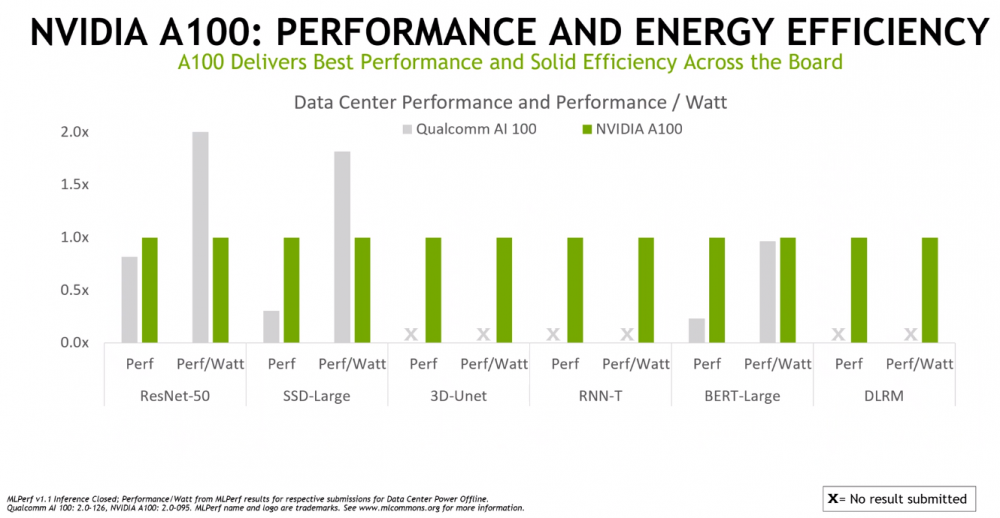
该公司测试了其即将推出的 Jetson AGX Orin 芯片,用于机器人和自动驾驶汽车等工作,其速度是其前身 Xavier 一代的 5 倍,并提供 2.3 倍的功率效率。
除了缺乏对来自各种供应商的每一代架构的测试之外,MLPerf 测试还缺少两个重要的组成部分——功耗和价格。阅读The Next Platform 的每个人都知道,HPC 中心对峰值性能非常感兴趣,但他们必须注意功耗和冷却,并且还知道超大规模生产者受到每瓦价格/性能的推动。等式的所有三个部分都必须存在。MLPerf 测试只说明了该等式的一部分。TPM 威胁要拆散 MLPerf,并将这些价格和功率数据添加到 MLPerf 结果中,并使用一些电子表格巫术作为诱使 ML Commons 从一开始就实际需要这些数据的手段。
微软宣布将于 2022 年 7 月发布 Windows Autopatch,这是一项旨在自动使 Windows 和 Office 软件保持最新状态的服务。
Windows Autopatch 是一项新的托管服务,免费提供给所有已拥有 Windows 10/11 Enterprise E3 或更高版本许可证的 Microsoft 客户。
“这项服务将使注册端点上的 Windows 和 Office 软件自动保持最新,无需额外费用。每个月的第二个星期二将是‘又一个星期二’,”高级产品营销经理 Lior Bela 承诺说微软
“Windows Autopatch 管理 Windows 10 和 Windows 11 质量和功能更新、驱动程序、固件和用于企业更新的 Microsoft 365 应用程序的部署组的所有方面。”
它将更新编排从组织转移到 Microsoft,规划更新过程(包括推出和排序)的负担不再由组织的 IT 团队承担。
Windows Autopatch 适用于所有受支持的 Windows 10 和 Windows 11 版本以及适用于企业的 Windows 365。
自动补丁如何工作?
Windows Autopatch 服务自动将组织的设备群分成四组设备,称为测试环。
“测试环”将包含最少数量的设备,“第一环”大约需要保持最新的所有端点的 1%,“快速环”大约 9%,“广泛环” 90% 的设备。
“这些环的数量是自动管理的,因此当设备来来去去时,环会保持其代表性样本。但是,由于每个组织都是独一无二的,企业 IT 管理员保留将特定设备从一个环移动到另一个环的能力, “贝拉补充道。
设置测试环后,将逐步部署更新,从测试环开始,并在验证期之后移动到更大的设备集,通过该验证期监控设备性能并与更新前的指标进行比较。
Windows Autopatch 部署环 (Microsoft)
Autopatch 还带有暂停和回滚功能,可以自动阻止更新应用到更高的测试环或自动回滚。
“每当任何 Autopatch 更新出现问题时,补救措施都会被整合并应用于未来的部署,从而提供 IT 管理团队无法轻易复制的主动服务水平。随着 Autopatch 提供更多更新,它只会变得更好,”Bela 发誓。
Microsoft 在 Windows Autopatch 常见问题解答中提供了更多详细信息,包括有关服务资格、先决条件和功能的信息。
工作时间:早上9:00-下午6:30
河南快米云网络科技有限公司
 公安备案编号:41010302002363
公安备案编号:41010302002363
Copyright © 2010-2023 All Rights Reserved. 地址:河南自由贸易区开封片区经济开发区宋城路122号