
通过编码使用动态独占代理主要有以下三步骤:
(1)先在会员中心上查看购买的动态独占代理,在“IP管理”中添加IP城市,获取的独占资源进行本地调试和验证;查看测试步骤>>
(2)参考代码样例请求动态独占代理;
(3)在程序中通过调用API接口获取独占代理,然后请求目标网站。
动态独占代理API接口一览
| 接口类型 | API | 描述 |
|---|---|---|
| 资源相关 | - monopolize_resources - monopolize_resources - monopolize_resources - monopolize_resources/newest_ips |
- 用POST调用接口申请独占资源 -用GET调用接口查询可用的独占资源 - 用DELETE调用接口释放独占资源 - 用PUT调用接口请求重拨独占资源 |
| 白名单相关 | - whitelist/query - whitelist/add - whitelist/del |
- 调用接口用于查询IP的白名单 - 调用接口用于添加IP的白名单 - 调用接口用于删除IP的白名单 |
| 资源信息查询 | - monopolize_resources/idle | - 用GET调用接口查询空闲的独占资源 |
动态独占代理相对动态独享代理,除了可以独享宽带和IP,还可以指定城市,因此资源相关接口与其他代理都不一样。
通过编码使用静态独享代理主要有以下三步骤:
(1)先在会员中心上查看购买的静态独享代理,进行本地调试和验证;查看测试步骤>>
(2)参考代码样例请求静态独享代理;
(3)在程序中通过调用API接口获取代理,然后请求目标网站。
静态独享代理API接口一览
| 接口类型 | API | 描述 |
|---|---|---|
| 资源相关 | - allocate - query - release |
- 调用 allocate申请代理IP资源 - 调用query查询IP资源池全部可用的IP信息 - 调用release释放申请到的IP,以便于再次进行IP申请。 |
| 白名单相关 | - whitelist/query - whitelist/add - whitelist/del |
- 调用 whitelist/query用于查询IP的白名单 - 调用whitelist/add用于添加IP的白名单 - 调用whitelist/del用于删除IP的白名单 |
| 资源信息查询 | - info/quota - resources |
- 调用 info/quota查询IP提取余量 - 调用extract查询平台可用的代理IP资源列表 |
通过编码使用动态共享代理主要有以下三步骤:
(1)先在提取工具或调试工具上提取动态共享代理,进行本地调试和验证;查看测试步骤>>
(2)参考代码样例请求动态共享代理;
(3)在程序中通过调用API接口获取代理,然后请求目标网站。
动态共享代理API接口一览
| 接口类型 | API | 描述 |
|---|---|---|
| 资源相关 | - allocate - extract - query |
- 调用 allocate申请代理IP资源 - 调用extract获取IP资源池全部可用的IP信息 - 调用query查询用户可用的代理IP资源列表 |
| 白名单相关 | - whitelist/query - whitelist/add - whitelist/del |
- 调用 whitelist/query用于查询IP的白名单 - 调用whitelist/add用于添加IP的白名单 - 调用whitelist/del用于删除IP的白名单 |
| 资源信息查询 | - info/quota - resources |
- 调用 info/quota查询IP提取余量 - 调用resources查询平台可用的代理IP资源列表 |
需要注意的是动态共享代理区分按时业务和按量业务,按时动态共享代理的默认提取接口是extract,按量动态共享代理的默认提取接口是allocate。
快米云代理IP提供了功能丰富的API接口,满足开发者在各种场景下的调用需求。
所有接口支持 HTTP 或者 HTTPS 请求,部分接口采用 GET 方法,部分接口采用 POST 方法;接口返回数据的格式支持文本、json、xml。
具体请参见接口文档。
对于代理提取API,您可以到提取工具在线生成API链接,内置到您的程序中:
其他接口请查看API文档,获取接口url和参数说明,自己生成API链接。
(1)浏览器测试
您可以把生成的API链接直接在浏览器里打开,查看返回结果。例如,您直接点击如下api链接
https://proxy.zzqidc.com/query?Key=0B***607
(2)命令行测试
如果您在linux系统下,可以通过curl命令请求API链接查看结果:
curl "https://proxy.zzqidc.com/allocate?Key=请改成您的Key
公共错误码
| 错误码 | 描述 |
|---|---|
| 1 | 未知错误 |
| 10 | 参数不合法! |
| 100 | 计划不存在或已过期! |
| 101 | 请求数量超过计划通道数! |
| 102 | 没有剩余的可用通道! |
| 103 | 资源不足 |
| 105 | 释放的IP数超过允许释放的IP数 |
查看API调用的代码样例 >>
英特尔预计将为今年晚些时候成为世界上最快的超级计算机之一的计算机提供下一代 CPU 和 GPU,但是当美国拖延已久的 Aurora 项目最终启动并运行时,它将在没有英特尔顶级架构师的情况下发生谁是其交付的关键。
根据周二在 LinkedIn 上发表的一篇帖子,英特尔技术负责人兼 Aurora 首席研究员 Robert Wisniewski 已离开这家半导体巨头,前往三星研发部门担任新的 HPC职位。虽然三星的研究部门专注于对 HPC 很重要的许多元素,但该公司并不以在超级计算中的突出作用而闻名,尽管这种情况可能会发生变化。
在回答The Register的问题时,英特尔发言人表示,这家芯片制造商“已经成立了一个新的领导团队”,并且“有望”在今年晚些时候在阿贡国家实验室交付美国能源部的 Aurora exascale 超级计算机项目。
英特尔没有具体说明谁接手了 Wisniewski 的职责,他自 2019 年以来一直在推动围绕 Aurora 的许多技术工作。Wisniewski 还是该公司所谓的 SuperCompute 团队的英特尔软件研究员。
Aurora 超级计算机对美国政府具有重要的战略意义,这在很大程度上是因为它将成为该国首批百亿亿级超级计算机之一。这意味着能够为关键研究项目提供每秒至少 1 exaflop 或 1 quintillion 浮点运算,范围从发现新的癌症治疗到模拟核聚变反应。
发生这种情况的同时,中国已经以1.3 exaflops 的峰值性能击败了美国,而不是一个,而是两个系统。
Aurora 对英特尔来说也具有重要的战略意义,英特尔作为该项目的主要承包商,将在超级计算机中推出其下一代 Xeon Scalable CPU、代号 Sapphire Rapids 和 Ponte Vecchio GPU 加速器。英特尔去年底表示,这些组件将使 Aurora 能够提供超过 2 exaflops的峰值性能,这将使其能够超越中国的系统,并一跃成为世界上最快的超级计算机之首。
虽然预计英特尔将在今年晚些时候安装 Aurora,但这只是在面临延迟之后。这家芯片制造商的系统合作伙伴 Cray 现在归 Hewlett Packard Enterprise 所有,最初于 2015 年宣布,它已达成一项协议,以在 2018 年完成时间表的情况下构建速度较慢的 Aurora 版本。但这一时间线滑到了 2021 年,当时英特尔将其高端 Xeon Phi 加速器Knights Hill淘汰,并转而使用其新的 Xe GPU 架构。
在英特尔在 2020 年年中表示制造问题已将其7nm 制造工艺的推出推迟了12 个月之后,Aurora 被推迟到 2022 年。该公司计划将其 7nm 工艺用于 Ponte Vecchio,但制造困境促使英特尔转向并仅将其 7nm 节点用于 GPU 的某些部分,而在其他方面则依赖代工竞争对手台积电。
英特尔今年是否真的会交付 Aurora,还有待观察。有理由抱有希望,因为该公司在过去几个月中报告了其 7nm 工艺的改进,并且在周一,该公司表示它在下一代节点的开发方面提前了计划。
至于 Wisniewski 的三星新工作,他表示他将为三星高级技术学院(也称为 SAIT)创建一个位于美国的新系统实验室。他在三星的正式头衔是高级副总裁、HPC 首席架构师和 SAIT 美国系统架构实验室负责人。
“我们将专注于克服 AI 和 HPC 应用程序的内存和通信障碍,并从系统的角度看待这些挑战,”他写道,并补充说他的团队正在招聘。
发言人说:“我们感谢罗伯特在英特尔任职期间所做的所有贡献以及他在 Aurora 方面的工作。” Argonne 的一位代表就人员配备的问题向英特尔提出了质疑。
Apache 再次尝试修复其用于 Java 应用程序的 Struts 2 框架中的一个关键远程代码执行漏洞——因为 2020 年发布的第一个补丁并没有完全解决问题。
Struts 2.0.0 到 2.5.29 版本中存在安全漏洞,攻击者可以利用它来控制易受攻击的系统。
山姆大叔的 CISA 已敦促组织尽快升级到补丁版本,例如 2.5.30。
Struts 被广泛使用,这个新旧安全漏洞类似于2017 年 大规模Equifax 漏洞中滥用的 OGNL 注入漏洞。
对象图导航语言 ( OGNL ) 是一种用于 Java 的表达式语言,除其他外,它允许程序员设置和获取 Java 对象属性。正如安全公司 Qualys去年警告的那样,“能够创建属性和更改代码执行,很容易出现严重的安全漏洞。”
早在 2020 年 12 月,GitHub 的漏洞猎手 Alvaro Munoz 和 Aeye 安全实验室的 Masato Anzai在 Struts 2 中发现了一个OGNL 注入漏洞,编号为CVE-2020-17530,在 CVSS 严重性方面获得了 9.8 分(满分 10 分)。
现在证明,该疏忽的补丁并不完整。本周我们了解到,如果应用程序使用该%{...}语法执行强制 OGNL 评估,仍然有可能因恶意用户输入而发生双重评估,从而导致漏洞利用。换句话说,修补过的漏洞仍然可能被精心制作的攻击者提供的数据滥用来劫持易受攻击的系统。
“对不受信任的用户输入使用强制 OGNL 评估可能会导致远程代码执行和安全性下降,”Apache 在 2020 年和现在的安全公告中指出。
当时,Apache 建议开发人员避免对不受信任的用户输入使用强制 OGNL 评估,并升级到 Struts 2.5.26,软件基金会表示将检查表达式评估以确保它不会导致双重麻烦。
最近,Chris McCown发现CVE-2020-17530 的修复程序不完整。结果,Apache 再次敲响了升级-Struts-now 的警报。
Java错误不断出现
Struts 漏洞是在其他 Java 缺陷之后出现的。
上个月末,VMware 威胁研究人员在基于 Java 的Spring Framework中发现了一个 RCE 漏洞,攻击者几乎立即开始利用该漏洞。Check Point 分析师仅在第一个周末就看到了大约37,000 次利用尝试,并表示全球约有 16% 的组织受到编程错误的影响。
最近,趋势科技研究人员表示,犯罪分子正在利用该漏洞运行 Mirai僵尸网络恶意软件。
与此同时,Palo Alto Networks 的 Unit42 安全分析师写道,他们预计被称为 Spring4Shell 的 Spring 漏洞“被完全武器化并被更大规模地滥用”,因为对该漏洞的利用是“直截了当的,所有相关的技术细节都已经消失在网上疯传。”
大量组织仍在努力修补广泛使用的 Apache 日志库中的 Log4j 漏洞。该漏洞于去年年底被发现,截至 3 月,不法分子仍在利用该漏洞安装后门和加密挖掘恶意软件。
据 Qualys 称,在 2021 年 12 月 Log4j 漏洞披露后的 72 小时内进行了近100 万次利用尝试。两个月后,30% 的 Log4j 实例显然仍然容易受到攻击。
在将入侵后工具下载到服务器、PC 之前,不法分子会在 Google 上搜索它们
据 Sophos 威胁研究人员称,Lockbit 勒索软件运营商在政府机构的网络中花费了近六个月的时间,删除日志并使用 Chrome 下载黑客工具,然后最终部署勒索软件。
在未具名的美国地区政府机构开始调查入侵之前大约一个月,网络犯罪分子删除了大部分日志数据以掩盖他们的踪迹。
但他们并没有删除所有日志,也没有删除浏览器搜索历史,这意味着他们留下了一些碎屑。
“Sophos 能够从那些未被干扰的日志中拼凑出攻击的叙述,这些日志提供了对一个不是特别复杂但仍然成功的攻击者的行为的亲密观察,”安全商店的 Andrew Brandt 和 Angela Gunn本周在攻击分析。
其他组织有望从这种入侵中学到一些东西,以避免类似的命运。对于两件事,对帐户使用多因素身份验证,以及限制远程桌面访问(例如,经过身份验证的 VPN 连接)可能有所帮助。
据 Sophos 称,不法分子通过远程桌面协议 (RDP) 服务闯入:防火墙被配置为提供对 RDP 服务器的公共访问。正如 Sophos 研究人员指出的那样,切入点“没什么了不起的”。没有确切说明不法分子是如何进入的——例如通过暴力破解弱密码、使用被盗凭证、窃听流氓内部人员或利用安全漏洞——但我们被告知入侵者设法劫持了本地服务器上的管理员帐户也具有 Windows 域管理员权限,这将使探索和破坏网络变得简单。
勒索软件团伙留下了他们在被征用的服务器和台式机上安装的各种合法远程访问工具的记录。起初,这些不法分子表现出对 ScreenConnect IT 管理套件的偏好,但随后他们转而使用 AnyDesk,Brandt 和 Gunn 指出,这可能是为了逃避网络上的反措施。
安全研究人员还发现了 RDP 扫描、利用和暴力破解密码工具,以及记录其成功使用的日志。该团伙似乎希望在该机构的机器中设置多条路径,以确保在一条或多条通道关闭时工作人员可以重新连接。
因此,识别和处理意外的远程桌面或远程命令连接可以在未来拯救您的组织。
“不寻常的远程访问连接,即使来自合法帐户,也可能是入侵的迹象,”Sophos 威胁研究总监 Christopher Budd 在给The Register的电子邮件中指出。“此外,网络内部的异常行为,特别是下载经常被攻击者滥用的强大合法工具可能是另一个迹象。”
网络犯罪分子的网络搜索显示,他们使用政府计算机查找并安装了多种入侵后工具和其他类型的恶意软件。这包括密码暴力破解器、加密矿工和盗版 VPN 客户端软件。
此外,Sophos 发现该团伙“使用 PsExec、FileZilla、Process Explorer 或 GMER 等免费软件工具来执行命令、将数据从一台机器移动到另一台机器以及杀死或破坏阻碍他们工作的进程的证据”。
Sophos 指出,该网络的技术人员也犯了一些错误。在一种情况下,他们在完成维护工作后使保护功能失效。这使得一些系统容易受到渗透者的干预,他们关闭了服务器和一些桌面上的端点安全产品,然后安装了远程访问工具来保持对机器的控制。接下来,数据被盗。
“在没有适当保护的情况下,攻击者安装 ScreenConnect 为自己提供远程访问的备份方法,然后迅速将文件从网络上的文件服务器泄露到云存储提供商 Mega,”Brandt 和 Gunn 写道。
好的,谷歌,我应该使用什么恶意软件?
Sophos 指出,经过五个月的谷歌搜索恶意软件并在该机构的网络上四处闲逛,犯罪分子的行为发生了“戏剧性的变化”。
日志显示,他们远程连接并安装了 Mimikatz,这是一个可以从 Windows 系统中提取帐户用户名和登录凭据的开源工具。这家安全商店补充说,它的防病毒产品首次尝试运行该软件,但显然“IT 部门没有注意到来自 Sophos 套件的警告”,并且通过受损帐户运行 Mimikatz 的其他尝试也奏效了。
此时,攻击者开始表现得更像是专业的网络犯罪分子,Sophos 还注意到 IP 地址位置扩大了。最终,分析将歹徒的 IP 地址追踪到伊朗、俄罗斯、保加利亚、波兰、爱沙尼亚和加拿大。Sophos 补充说,这些可能是 Tor 出口节点。
在大约五个月的时间里,政府机构的 IT 团队注意到系统反复重启,并且“表现得很奇怪”。它开始调查和分割网络,以保护已知良好的机器免受其余机器的影响。
但 IT 团队在重建网络期间禁用了 Sophos Tamper Protection,安全供应商表示“在那之后事情变得很疯狂”。
在入侵开始后的第 6 个月的第一天,网络犯罪分子运行了 Advanced IP Scanner,开始通过网络横向移动到“多个敏感服务器”,并使用受损的凭据通过 LockBit 加密机器并发送赎金记录。
“几分钟之内,攻击者就可以访问大量敏感人员并购买文件,攻击者正在努力进行另一次凭证转储,”Brandt 和 Gunn 写道。
第二天,政府机构召集了 Sophos 安全分析师,并开始与他们合作关闭提供远程访问的服务器并删除恶意软件。
“在调查过程中,”Sophos 两人写道,“一个因素似乎很突出:目标的 IT 团队做出了一系列战略选择,使攻击者能够自由移动并无障碍地访问内部资源。部署 MFA 会阻碍威胁参与者的访问,防火墙规则也会在没有 VPN 连接的情况下阻止远程访问 RDP 端口。
“及时响应警报,甚至是有关性能下降的警告,可以防止许多攻击阶段产生效果。禁用端点安全软件上的篡改保护等功能似乎是攻击者完全删除保护并完成其攻击所需的关键杠杆。无阻碍的工作。”
Sophos 的文章包括从这次感染中收集的一系列危害指标,供您在网络上进行扫描。
阿里云已开始接受客户的请求,以预览由其去年发布的国产 Arm CPU 提供支持的实例类型。
Yitian 710处理器拥有 128 个兼容 Armv9 的 CPU 内核,可在高达 3.2 GHz 的频率下运行。我们被告知,8 个 DDR5 通道和 96 个 PCIe 5.0 通道,占芯片上 600 亿个晶体管中的一部分,这些晶体管是使用 5nm 工艺制造的。
阿里云没有大张旗鼓地透露,它已经准备好在其云中的服务器中启动芯片。这些芯片设置为支持名为 g8m 的弹性计算服务 (ECS) 实例类型,该实例类型提供 1、2、4、8、16、32、64 或 128 个 vCPUS 的变体——每个 vCPU 对应一个物理内核。
仅限邀请的预览版仅提供以下变体之一:zzqidc.com 虚拟机 - 具有 4 个 vCPU、16 GB 内存和 3 Gbit/秒网络带宽(可突增至 10 Gbit/s)的装备。实例将以 2.75 GHz 运行 CPU 内核——略低于硅的速度上限。
预览版仅运行两个月,之后由 Yitian 提供支持的实例将消失。阿里云在试用期间警告不要运行生产工作负载。仅提供 100 个实例,阿里巴巴表示它们是先到先得的。这些虚拟机托管在阿里巴巴在中国的杭州专区。
如果您申请,阿里云并没有完全解释您的目标。该公司表示,zzqidc.com实例提供的“成本效益比”比其当前一代由英特尔和 AMD 处理器提供支持的通用实例高出 100%,但并未解释该比率的衡量标准。g8m 实例没有详细定价。
阿里巴巴也没有提供任何关于试用何时结束的提示,以及新的实例类型更广泛地可用。
阿里云落后于亚马逊网络服务,后者已经提供了许多不同实例类型的第二代 Arm 驱动的 Graviton CPU,并在绘图板上拥有第三代Arm 处理器。微软上周推出了基于 Arm 的 Azure 产品,甲骨文云也有由 Ampere 芯片驱动的Arm 服务器。
然而,这家中国巨头现在正在参与其中——这进一步证明了 Arm 驱动的服务器非常适合云原生工作负载的想法。这一主张在中国可能会得到很好的支持,在中国,独立于来自美国的技术是一个国家目标。

由于以太网的局限性,谷歌从 InfiniBand 和 Cray 的“Aries”互连中汲取了最佳创意,并创建了一个名为 Aquila 的新分布式交换架构和一个新的 GNet 协议栈,该协议栈提供了搜索引擎巨头所提供的那种一致和低延迟几十年来一直在寻找。
这是谷歌所做的事情让 IT 行业的每个人都停下来思考的重要时刻之一。
2003 年的Google 文件系统。2004 年的MapReduce分析平台。2006 年的BigTable NoSQL 数据库。2009 年的仓库级计算概念。2012 年的Spanner分布式数据库。2015 年的Borg集群控制器以及Omega 调度程序2016 年的附加组件。2015 年的Jupiter定制数据中心交换机。2017 年的Espresso边缘路由软件堆栈。仙女座2018 年的虚拟网络堆栈。Google 从未发表过关于其 Colossus 或 GFS2 文件系统、GFS 的继任者和 Spanner 的基础的论文,但它确实在上面的 Spanner 论文中提到了它,并且它确实在冠状病毒期间提供了视频演示去年有关 Colossus 的大流行,以帮助将 Google Cloud 与同行区分开来。
两个旁白:看看问题出在哪里。谷歌正在摆脱数据处理和支撑它的系统软件,并通过调度进入数据中心和边缘的网络,因为它向世界展示了它的手工和技术实力。
谷歌现在另一个有趣的事情是,它没有像所有早期的论文那样透露它在几年前做了什么,而是它现在正在做什么来为未来做准备。计算高层对人才的竞争如此激烈,以至于谷歌需要这样做以吸引那些可能会去创业公司或其众多竞争对手之一的天才。
无论如何,搜索引擎和广告巨头已经有一段时间没有在我们所有人身上投下一篇大论文了,但谷歌再次通过一篇描述Aquila的论文来做到这一点,这是一种低延迟的数据中心结构,它使用自定义交换机和接口逻辑和一个称为 GNet 的自定义协议,与该公司长期以来部署的基于以太网的、数据中心范围的 Clos 网络相比,它提供了低延迟、更可预测和显着降低的尾部延迟。
借助 Aquila,如果您在阅读这篇论文时稍微眯起眼睛,谷歌似乎已经完成了英特尔可能试图在 Omni-Path 上做的事情,该论文发表在最近举行的网络系统设计与实施 (NSDI) 会议上由 USENIX 协会。具体来说,它借鉴了超级计算机制造商 Cray 创建并于 2013 年 11 月在“Cascade”CX30 机器中宣布的“Aries”专有互连的一些主题。
当然,您会记得,英特尔早在 2012 年 4 月就从 Cray 购买了 Aries 互连,并计划将其部分技术与其 Omni-Path InfiniBand 变体合并,该变体是在 2012 年 1 月从 QLogic 收购该业务时获得的. Aries 具有自适应路由和少量拥塞控制(有时会变得混乱)以及蜻蜓式全对全拓扑,这与超大规模和云构建者使用的 Clos 网络拓扑以及 Hyper-X 网络有时不同由 HPC 中心使用,而不是蜻蜓或胖树拓扑。在不重新连接整个集群的情况下为蜻蜓网络增加容量是比较困难的,但如果你正在安装机器,那就完全没问题了。Clos all-to-all 网络允许相当容易地添加机器,但是机器之间的跳数以及因此的延迟与蜻蜓网络不同。
Cray 的前首席技术官 Steve Scott 领导了其“SeaStar”和“Gemini”以及前面提到的 Aries 互连的设计,这些互连是 Cray XT3、XT4 和 XC 机器的核心,他于 2013 年加入谷歌,直到 2014 年才重新加入 Cray,通过“Rosetta”Slingshot 互连引领其超级计算复兴。斯科特告诉我们,作为谷歌平台组的一员,他非常欣赏网络中尾部延迟的细微之处,但看起来斯科特给他们留下了深刻的印象,即针对特定工作调整的专有协议的重要性,高基数切换绝对峰值带宽,拥塞控制和自适应路由的必要性,比互联网巨头使用的东西更脆弱,还有蜻蜓拓扑。(Scott 于 2020 年 6 月以技术研究员的身份加入 Microsoft Azure,可以合理地预期这家云巨头在 Scott 的帮助下完成了与网络相关的事情。)
简而言之,英特尔花了 2.65 亿美元从 QLogic 和 Cray 购买了这些网络资产,天堂只知道在将 Omni-Path卖给 Cornelis Networks 之前还有多少开发和营销,现在可能希望它发明了像 Aquila 这样的东西。
这个 Aquila 数据中心结构有很多层,目前处于原型阶段,目前还不清楚这将如何与英特尔与谷歌共同设计的“埃文斯山”DPU进行交互和交互。超大规模可能已经在其服务器机群中进行部署。事实证明,位于 Aquila 结构核心的融合交换机/网络设备和 Mount Evans DPU 在各自的路线图上有一个共同的目的地,或者它们在平行的道路上行驶,直到轮胎爆胎。
Aquila 是eagle的拉丁词,它明确地不在支持 Internet 的以太网、IP 或 TCP 和 UDP 协议之上运行,或者尽管如此。(对于这些嵌套协议之间的差异的一个很好的图像,这里有一个很好的解释:“想象一个气动管消息系统。以太网是用于发送消息的管,IP 是管中的信封,而 TCP/ UDP是信封里的一封信。 ”
忘记这一切。Google 全力以赴,创建了它所谓的基于单元的第 2 层交换协议和相关的数据格式,而不是数据包。实际上,一个单元比一个数据包还小,这也是谷歌能够通过 Aquila 结构获得更好的确定性性能和更低的服务器节点之间链路延迟的原因之一。单元格格式针对 RDMA 网络中常用的小数据单元进行了优化,并具有架顶式交换机 ASIC 和网络接口卡的融合网络功能,跨越 Aquila 互连原型的 1,152 个节点规模,它可以平均 4 微秒内读取 RMA。
这种融合的交换机/NIC 野兽、单元数据格式、使用其自己的称为 1RMA 的 RDMA 变体非常有效地处理它的 GNet 协议、带外软件定义的网络结构和蜻蜓拓扑创建了一个自定义的、高速度互连与如果 Aries 和 InfiniBand 在超大规模数据中心有一个爱的孩子,并且这个孩子可以在必要时在其边缘说话和听到以太网会发生什么非常相似。
让我们从 Aquila 硬件开始,然后沿着堆栈向上工作。首先,谷歌不想在这上面花很多钱。
“为了维持一个规模适中的团队的硬件开发工作,我们选择在同一硅片中构建具有 NIC 和交换机功能的单芯片,”在 Aquila 工作的 25 名谷歌研究人员在论文中解释道。“我们的基本见解和出发点是,可以以适度的额外成本将中基交换机集成到现有的 NIC 芯片中,并且可以将许多称为 ToR-in-NIC (TiN) 芯片的这些 NIC/交换机组合连接在一起通过 Pod 中的铜背板,一个与传统架顶式 (ToR) 交换机大小相当的外壳。然后,服务器可以通过 PCIe 连接到 Pod 以实现其 NIC 功能。TiN 交换机将通过优化的第 2 层协议 GNet 提供与同一 Clique 中的其他服务器的连接,并通过标准以太网提供与其他 Clique 中的其他服务器的连接。”
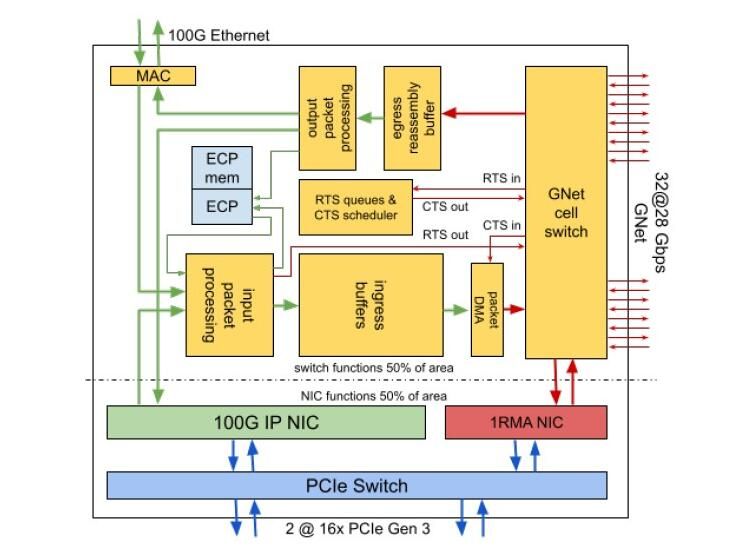
这个“torrinic”芯片上有很多东西。Amin Vahdat 是谷歌系统和服务基础架构团队的工程研究员兼副总裁,在此之前曾长期领导网络基础架构团队,去年这个时候告诉我们,SoC 是新的主板,而创新的焦点,我们并不感到惊讶的是,每个 Aquila 芯片实际上都是一个复合体,其中两个 TiN 在同一个封装中(但不一定在同一个母鹿上,请注意)。Vahdat 是 Aquila 论文的作者之一,无疑推动了开发工作。
如您所见,设备中有一对 PCI-Express 3.0 x16 插槽,允许将一个 256 Gb/秒的胖管道连接到单个服务器或两个 128 Gb/秒的半胖管道用于两台服务器。位于此 PCI-Express 交换机另一侧的是一对网络接口电路——一个讲 100 Gb/sec IP 并且可以通过芯片讲以太网,另一个讲专有 1RMA 协议并连接到 GNet细胞开关。
该单元交换机有 32 个端口,以 28 Gb/秒的速度运行——正如谷歌在上面指出的那样,没有交换机那么多端口,也没有端口那么快。取消编码开销后,这些 GNet 单元交换通道以 25 Gb/秒的速度运行,这与 IBM Power9 处理器上的“Bluelink”OpenCAPI 端口以及“Ampere”A100 GPU 中的 NVLink 3.0 管道中的通道相同。和相关的 NVSwitch 开关。在这些 25 Gb/秒的通道中,有 24 条用于通过铜线链路连接 pod 中的所有服务器节点,并且有 8 条链路可用于将多达 48 个 pod 互连到单个 GNet 结构中,称为“集团”,使用光链路。Cray 和现在谷歌使用的 Dragonfly 拓扑结构明确设计用于限制光收发器和电缆的数量,以便远程连接服务器 pod。
Aquila TiN 具有输入和输出数据包处理引擎,如果来自单元交换机的数据需要离开 Aquila 结构并进入 Google 的以太网网络,则可以与 IP NIC 和以太网 MAC 连接。
谷歌表示,Aquila 织物的单芯片设计旨在降低芯片开发成本,同时“简化库存管理”。在冠状病毒大流行期间一直在等待交换机或 NIC 交付的任何人都知道 Google 在说什么。NIC 的缺乏肯定会减缓服务器的销售。几个月前情况非常糟糕,我们通过经销商听说的一些 HPC 商店正在转向英特尔的 100 Gb/秒 Omni-Path 设备,因为它至少有货。
这种融合网络架构的要点是,谷歌在其数据中心规模的 Clos 网络中嵌套了一个非常快速的蜻蜓网络,该网络基于叶/脊拓扑,不是全对全网络,但确实允许一切都以具有成本效益和可扩展的方式相互连接。
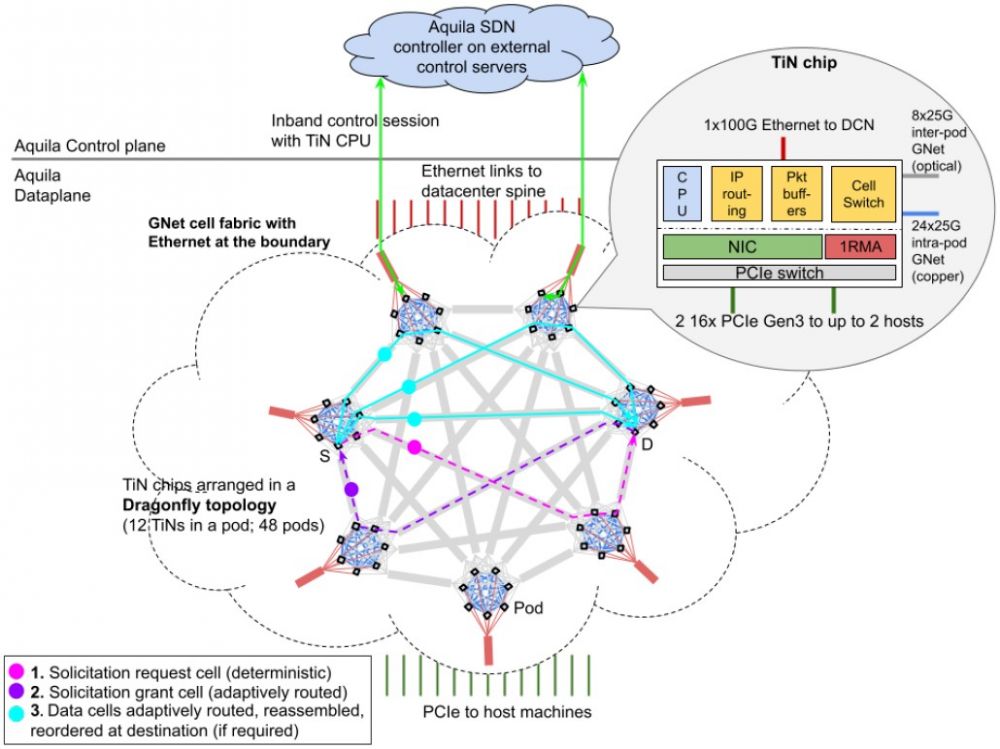
谷歌表示,光链路允许 Aquila 吊舱相距 100 米,并在互连吊舱之间施加 30 纳秒(谷歌称纳秒)的每跳延迟,这是通过前向纠错减少噪音并产生一些潜伏。
如今,大多数交换机都内置了计算功能,谷歌表示大多数交换机都有一个多核 64 位处理器,其主内存介于 8 GB 和 16 GB 之间。但是,通过使用外部 SDN 控制器并使用 Aquila 芯片封装上的本地计算作为每个 TiN 对的端点本地处理器,Aquila 封装可以使用 2 MB 的 32 位单核 Cortex-M7 处理器专用 SRAM 来处理 SDN 堆栈的本地处理需求。运行 GNet 堆栈的外部服务器没有泄露,但这是 Google 的常见设计。
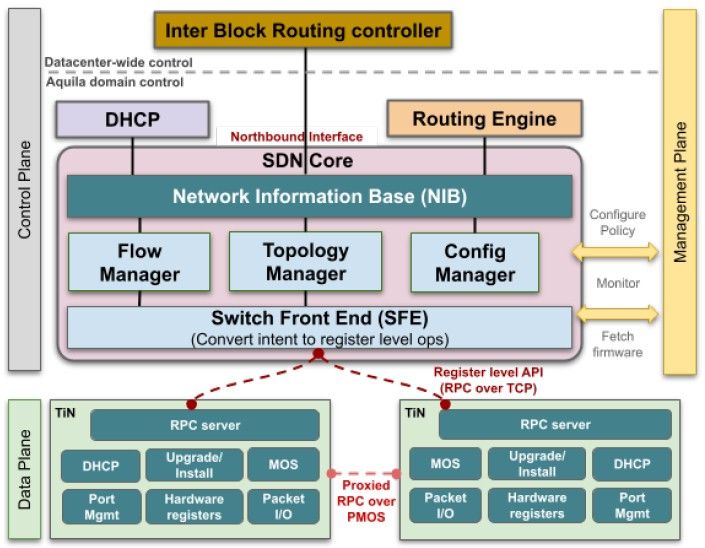
SDN 软件是用 C 和 C++ 编写的,由大约 100,000 行代码组成;Aquila 芯片运行 FreeRTOS 实时操作系统和 lwIP 库。该软件将所有低级 API 公开给 SDN 控制器,该控制器可以访问并直接操作设备的寄存器和其他元素。谷歌补充说,将 Aquila 的固件分发到控制器上,而不是设备上,是绝对有意为之的,其想法是 TiN 设备可以启动 GNet 和以太网链接并尝试链接到网络上的 DHCP 服务器,并等待来自中央 Aquila SDN 控制器的进一步配置命令。
关于 Aquila 网络的一个有趣之处在于,由于它是蜻蜓拓扑,因此您必须从一开始就配置网络中的所有节点,或者每次添加机器时都必须重新连接以获得网络的全部带宽. (这是全对全网络的缺点。)所以谷歌会这样做,然后根据需要添加服务器。这是服务器和网络的示意图,看起来像所有的吊舱: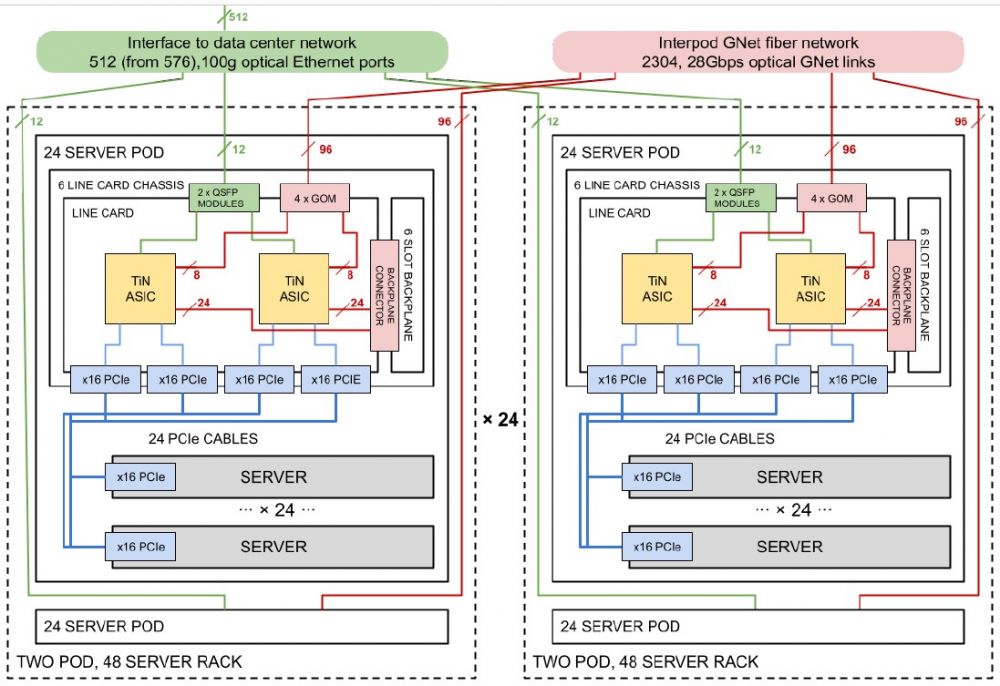
Aquila 设置在一个机架中有两个 24 个服务器的 Pod,在一个 clique 中有 24 个机架。谷歌正在使用其标准服务器机箱,其适配器卡上有 NIC,在这种情况下是一个 PCI 适配器卡,它链接到一个交换机机箱,该机箱在六个适配器卡上具有十几个 T1N ASIC。蜻蜓网络的第一层是在机箱背板上实现的,有96个光GNet链路从吊舱出来,将48个吊舱连接在一起,全对所有,每个有两条路由。
让许多 ASIC 实现网络的一个副作用是任何给定 ASIC 的爆炸半径都非常小。如果两台服务器共享一个 T1N 并且 T1N 包有两个 ASIC,那么一个包的故障只会淘汰四台服务器。如果一个有 48 台服务器的机架中的一个架顶式交换机烧毁,那么 48 台服务器就会停机。如果整个 Aquila 交换机机箱发生故障,仍然只有 24 台机器被淘汰。
展望未来,谷歌正在研究在未来的 Aquila 设备中为 TiN 设备添加更多计算能力,每个 NIC 的数量相当于一个 Raspberry Pi,这样它就可以运行 Linux。这将允许谷歌向网络添加更高级别的 P4 编程语言抽象层,这是它绝对想做的。
在早期测试中,Aquila 结构能够在结构往返时间(网络术语中的 RTT)中具有低于 40 微秒的尾部延迟,并且在键值上跨 500 台主机的远程内存访问时间低于 10 微秒名为 CliqueMap 的商店。与现有 IP 网络相比,即使在高负载下,该尾部延迟也小 5 倍。
最后一个想法。Aquila 网络的规模并没有那么大,更多地扩展计算将意味着扩展 T1N ASIC 具有更多端口,并且可能(但不一定)具有更高的信号速率以增加带宽以匹配 PCI-Express 5.0 速度. (毕竟这是一个原型。)我们认为谷歌会选择更高的基数而不是更高的带宽,或者至少将差异分开。
然而,还有另一个性能因素需要考虑。七年前,当 Google 谈论 Borg 时,它在一个 pod 中有 10,000 到 50,000 台服务器,这已经很多了。但是谷歌使用的服务器每个插槽可能有几个到十几个核心,每台机器可能有两个插槽。目标很高,称其为平均 20 个内核。但是今天,我们每个服务器插槽有几十个核心,每个插槽有几百个核心,所以可能只需要几千个节点就可以运行除了谷歌最大的工作之外的所有工作。甚至大型作业也可以跨 Aquila pod 分块,然后通过常规以太网链路聚合。在那段时间内,对于整数工作,内核数量增加了 10 倍,每时钟指令 (IPC) 增加了大约 2 倍;浮点性能提高了更多。将其称为每个节点的性能提高 20 倍。据我们所知,谷歌的 pod 大小不需要拉得太远。
更重要的是,(O)1000 集群,作为技术论文的缩写集群,大约有数千个节点,即使它们无法运行最大的模型,也足以完成重要的 HPC 和 AI 工作负载。看看哪些工作适合 Aquila 结构,哪些不适合,这将会很有趣,有趣的是,这项技术可能非常适合许多初创公司、企业、学术和政府企业的规模。因此,即使 Aquila 现在无法扩展,它也可能成为 Google 云上非常高性能的 HPC 和 AI 服务的基础,其中 (O)1000 恰到好处。

据观察,一种名为 Enemybot 的新型基于 Mirai 的僵尸网络恶意软件通过调制解调器、路由器和物联网设备中的漏洞增加了受感染设备的数量,而操作它的威胁者称为 Keksec。
特定的威胁组织专门从事加密挖掘和 DDoS;两者都受到可以嵌套在物联网设备中并劫持其计算资源的僵尸网络恶意软件的支持。
Enemybot 具有字符串混淆功能,而其 C2 服务器隐藏在 Tor 节点后面,因此在此时映射并删除它是相当具有挑战性的。
尽管如此, Fortinet的威胁分析师还是在野外发现了它 ,他们对该恶意软件进行了采样、分析,并发布了一份关于其功能的详细技术报告。
敌人机器人的能力
当设备被感染时,Enemybot 首先连接到 C2 并等待命令执行。大多数命令都与 DDoS(分布式拒绝服务)攻击有关,但恶意软件并不严格限于此。
更具体地说,Fortinet 提供了以下支持的命令集:
ADNS – 执行 DNS 放大攻击
ARK – 对游戏“ARK: Survival Evolved”的服务器进行攻击
BLACKNURSE – 用目标端口不可达 ICMP 消息淹没目标
DNS – 使用硬编码 DNS UDP 查询的泛洪 DNS 服务器
HOLD – 使用 TCP 连接淹没目标并将它们保持指定时间
HTTP – 用 HTTP 请求淹没目标
JUNK – 用随机的非零字节 UDP 数据包淹没目标
OVH – 使用自定义 UDP 数据包淹没 OVH 服务器
STD – 用随机字节 UDP 数据包淹没目标
TCP – 使用带有欺骗源头的 TCP 数据包淹没目标
TLS – 执行 SSL/TLS 攻击
UDP – 使用带有欺骗源头的 UDP 数据包淹没目标
OVERTCP – 使用随机数据包传送间隔执行 TCP 攻击
STOP – 停止正在进行的 DoS 攻击
LDSERVER – 更新下载服务器以获取漏洞利用负载
SCANNER – 通过 SSH/Telnet 暴力破解和漏洞利用传播到其他设备
SH - 运行 shell 命令
TCPOFF/TCPON – 在端口 80、21、25、666、1337 和 8080 上关闭或打开嗅探,可能是为了收集凭据

Enemybot 和 Mirai 扫描仪代码比较 (Fortinet)
针对 ARK 游戏和 OVH 服务器的命令特别令人感兴趣,这可能表明针对这些公司的勒索活动。
此外,LDSERVER 命令允许威胁参与者推出新的 URL 以处理下载服务器中的任何问题。这是值得注意的,因为大多数基于 Mirai 的僵尸网络都有一个固定的、硬编码的下载 URL。
有针对性的拱门和缺陷
Enemybot 针对多种架构,从常见的 x86、x64、i686、darwin、bsd、arm 和 arm64,到 ppc、m68k 和 spc 等稀缺和过时的系统类型。
这对于恶意软件的传播能力非常重要,因为它可以识别枢轴点的架构并从 C2 中获取匹配的二进制文件。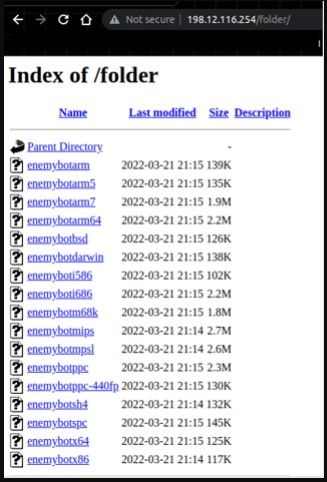
在暴露的下载服务器
(Fortinet)中看到的二进制文件
在目标漏洞方面,Fortinet 发现采样变体之间的集合存在一些差异,但无处不在的三个是:
CVE-2020-17456:Seowon Intech SLC-130 和 SLR-120S 路由器中的严重 (CVSS 9.8) 远程代码执行 (RCE) 漏洞。
CVE-2018-10823:影响多个 D-Link DWR 路由器的高严重性 (CVSS 8.8) RCE 漏洞。
CVE-2022-27226:影响 iRZ 移动路由器的高严重性 (CVSS 8.8) 任意 cronjob 注入。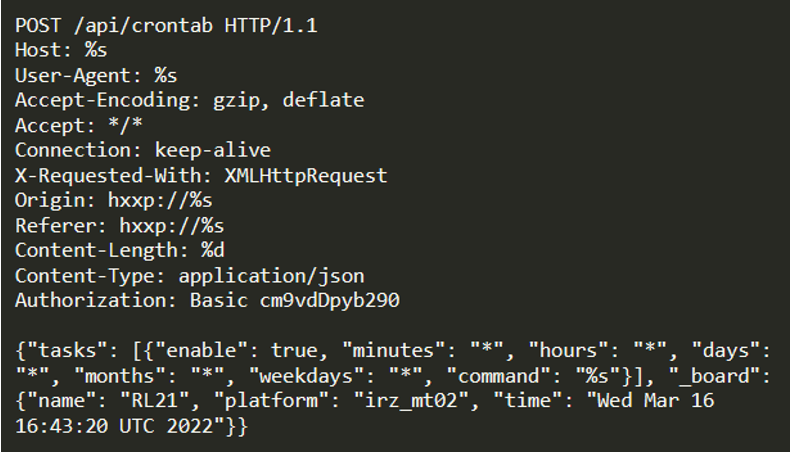
修改目标设备 (Fortinet)上的 crontab
根据变体的不同,Enemybot 中可能存在或不存在的其他缺陷是:
CVE-2022-25075 到 25084:一组针对 TOTOLINK 路由器的缺陷。Beastmode 僵尸网络也利用了相同的集合。
CVE-2021-44228/2021-45046:Log4Shell 和后续针对 Apache Log4j 的严重漏洞。
CVE-2021-41773/CVE-2021-42013:针对 Apache HTTP 服务器
CVE-2018-20062:针对 ThinkPHP CMS
CVE-2017-18368:针对 Zyxel P660HN 路由器
CVE-2016-6277:针对 NETGEAR 路由器
CVE-2015-2051:针对 D-Link 路由器
CVE-2014-9118:针对 Zone 路由器
NETGEAR DGN1000 漏洞利用(未分配 CVE):针对 NETGEAR 路由器
阻止僵尸网络
为防止 Enemybot 或任何其他僵尸网络感染您的设备并将其招募到恶意 DDoS 僵尸网络,请始终为您的产品应用最新的可用软件和固件更新。
如果您的路由器变得无响应,互联网速度下降,并且比平时更热,您可能正在处理僵尸网络恶意软件感染。
在这种情况下,在设备上执行手动硬重置,进入管理面板更改管理员密码,最后直接从供应商的网站安装最新的可用更新。
工作时间:早上9:00-下午6:30
河南快米云网络科技有限公司
 公安备案编号:41010302002363
公安备案编号:41010302002363
Copyright © 2010-2023 All Rights Reserved. 地址:河南自由贸易区开封片区经济开发区宋城路122号